A l’occasion de Culture futur 2019 l’équipe de la Turbine a remis à jour l’atelier Data Soundsystem que nous avions réalisé pour l’édition 2015. Il a été testé en septembre dernier auprès du public du festival et réédité avec les étudiants du Master 2 innovation de l’IAE de Grenoble.
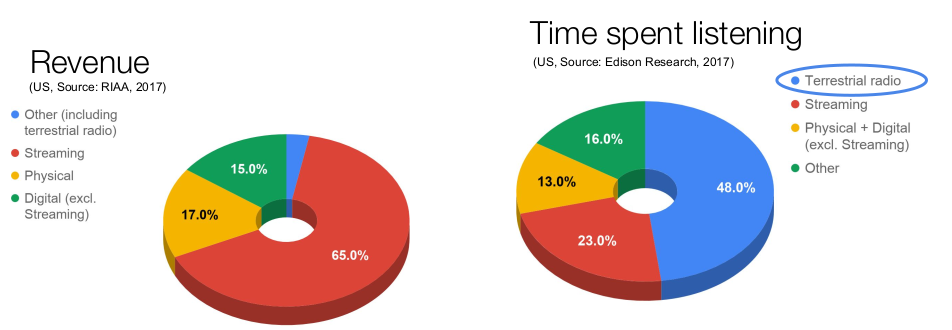
En 4 ans les choses ont changé, le streaming s’est massivement imposé et les algorithmes de recommandation musicale sont devenus incontournables pour proposer une expérience d’écoute qui permette à l’auditeur d’explorer des catalogues de millions de titres, en fonction de leurs goûts, activités ou des pratiques d’écoute de profils similaires. Bien sûr, ces algorithmes ne résument pas à eux-seuls les pratiques d’écoute musicale en ligne : les plateformes de streaming musical proposent toujours l’écoute d’albums, mais aussi des radios et des playlists concoctées par des curateurs ou programmeurs. Néanmoins, l’importance des données et de leur analyse est croissante pour ces plateformes !
.
La recommandation musicale reste un sujet de pointe pour les data scientists. Tous les ans, à la conférence annuelle de l’International Society for Music Information Retrieval, chercheurs, ingénieurs, plateformes de streaming et autres services de musique numérisée partagent leurs avancées. Car leur défi reste de taille. Trop souvent les algorithmes échouent à proposer le bon équilibre entre nouveautés, sons familiers, morceaux populaires et diversité des genres.
En mode automatique sur Deezer, Youtube ou Spotify, combien de fois se sent-on enfermé dans un tunnel de morceaux au son similaire ? Pourquoi se voir proposer les plus gros artistes du moment plutôt que des petites pépites que l’on adorerait découvrir ? Pourquoi cette impression de recommandation mécanique et grossière ?
Après avoir discuté avec Pierre René Lherisson (coworker à la Turbine) autour de sa thèse, nous nous sommes inspirés de la présentation de trois chercheurs et praticiens qui brossent l’état de la recommandation musicale par les données.
.
Des datas pour cataloguer la musique et… les utilisateurs
Les données sur la musique sont surabondantes. Au-delà des titres, noms des artistes et genres, les grosses bases de données et plateformes analysent le signal sonore traquant les similarités en terme de tempo, fréquences sonores. Elles scannent les paroles et pochettes, mais aussi les réseaux sociaux, les classements et playlists. Des critères de danseabilité, énergie sont assignés.
Ces sont parfois plus de 300 informations qui sont associées à un morceau en métadonnées. Pour s’en faire une idée et voir l’utilisation possible de ces métadonnées, il suffit de consulter des applications comme Musicaldata ou d’explorer Musicmap ou Musicroamer.
Mais il s’agit aussi de cataloguer les utilisateurs.
Nos habitudes d’écoute, nos humeurs sont sondées pour établir des profils. Mais l’expérience reste pauvre et souvent inférieure à ce que peut produire la recommandation humaine. Un programmateur radio, un journaliste spécialisé, un ami passionné sont souvent de bien meilleurs curateurs.
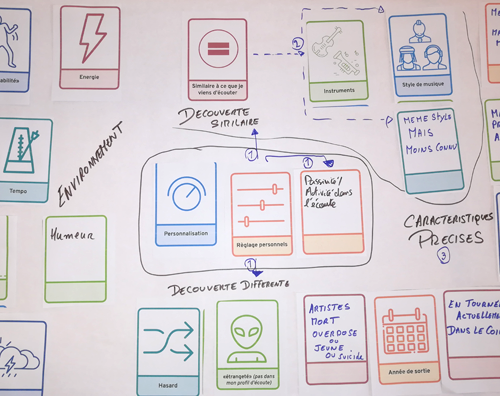
C’est avec ces quelques notions en tête que nous avons demandé à nos participants de l’atelier Data Soundsystem de réfléchir à ce qui les frustrait et d’imaginer les algorithmes qui leur conviendraient.

Rob Dobi Your scene sucks
Et si on mettait la main dans les algorithmes ?
C’est avec cette proposition de remettre de l’humain dans la machine, plutôt que d’identifier de nouvelles sources de données, que les participants ont travaillé à des scénarios algorithmiques.
Première constatation, donner du pouvoir sur la recommandation musicale semble intéresser tout le monde. S’abandonner à une recommandation automatique n’est pas suffisant et l’on souhaite pouvoir choisir un mode actif. Et quelques pistes prometteuses sont ressorties.
.
Plus de données contextuelles pour plus de personnalisation
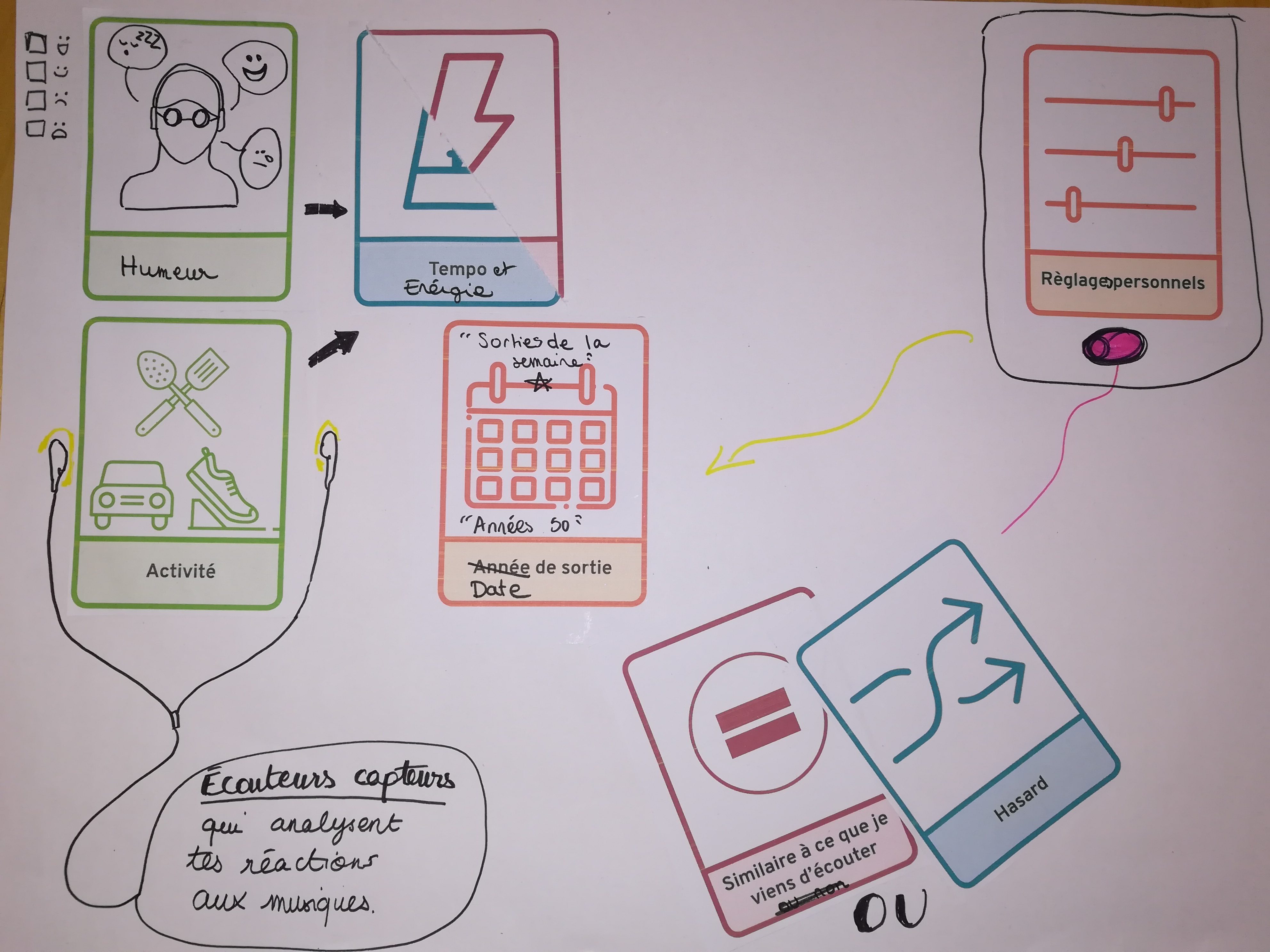
Les données d’environnement de la personne sont des données de base : l’humeur, l’activité, la météo sont à prendre en compte pour des recommandations plus adaptées. Certains proposent même que des capteurs soient intégrés dans les écouteurs.
L’algorithme, console de mixage de ses choix
Que ce soit pour trouver de nouveaux morceaux dans son univers ou pour se laisser surprendre, avoir la main est intéressant pour doser les caractéristiques voulues dans un sens ou dans l’autre. Beaucoup des scénarios préconisent la possibilité de pouvoir faire des réglages très précis et de mixer les styles. Avoir la possibilité de mémoriser ses préférences de mix est aussi souhaité.
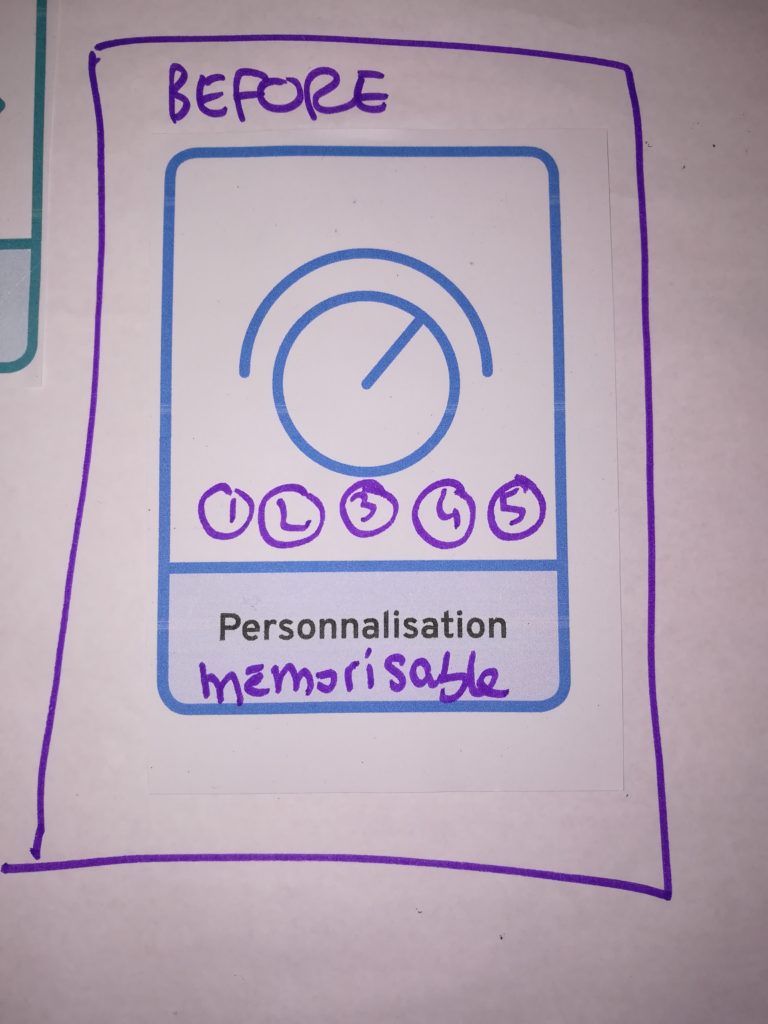
Mixes de recommandation mémorisés 
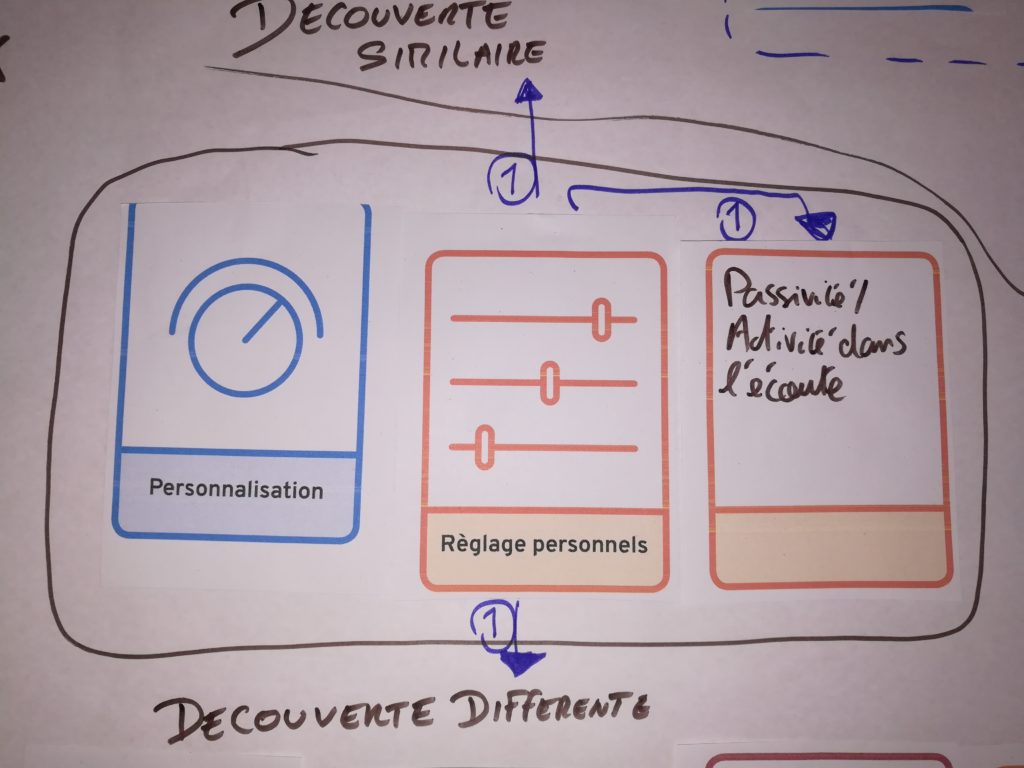
Console de choix 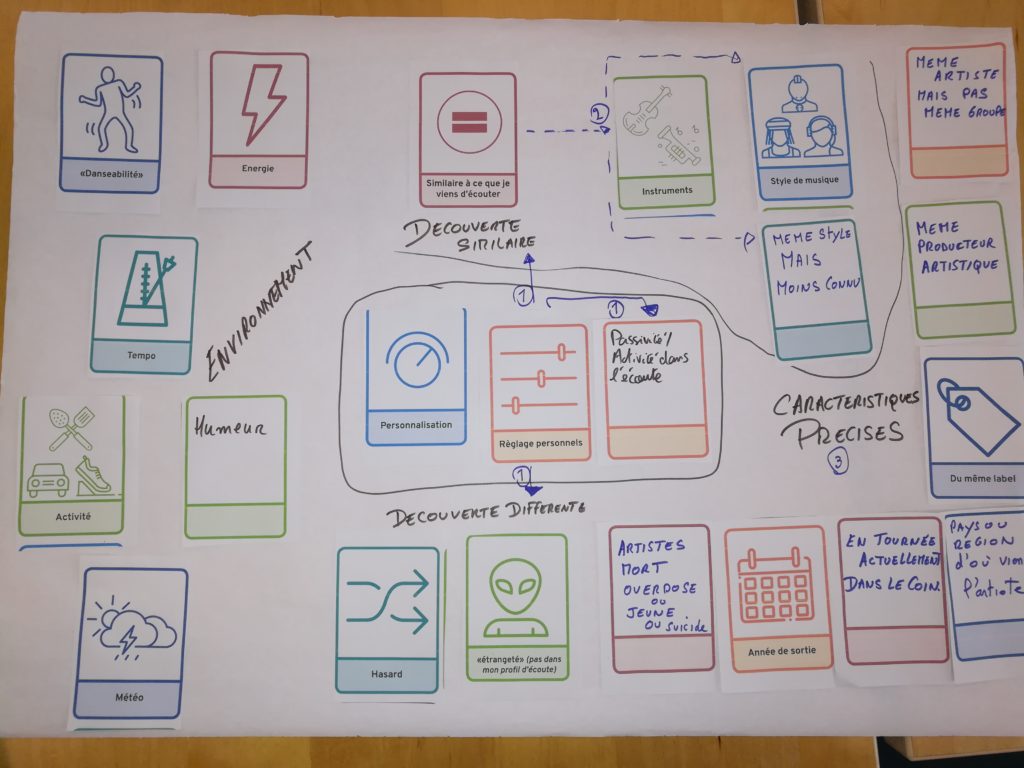
Console de mix de recommandations
.
Interagir en cours d’écoute et recaler l’algorithme
Autre piste, pouvoir intervenir en cours d’écoute directement dans le player et aller plus loin que le binaire j’aime/j’aime pas. Pour indiquer des nuances à l’algorithme avec « C’est pas le moment » ou « moins souvent ». Mais il a été imaginé également de recaler l’algorithme après coup, à partir de l’historique des recommandations automatiques pour éventuellement barrer des critères de recommandation, ajuster la fréquence des propositions, etc.
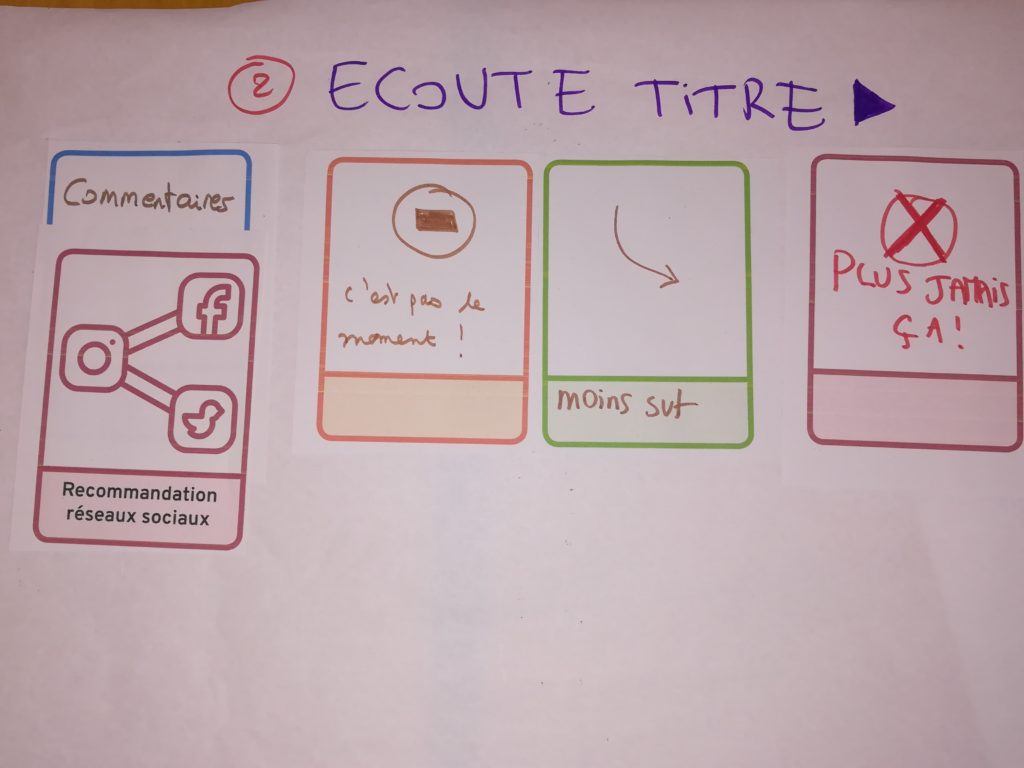
Intervenir dans le player 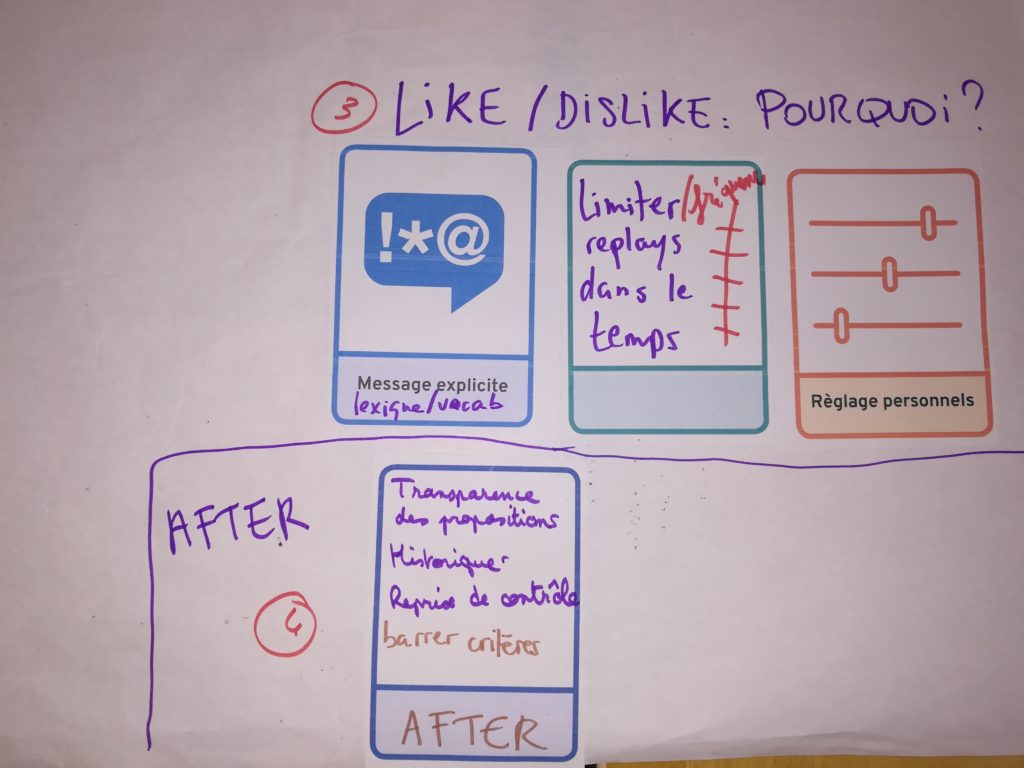
Like-Dislike
Les propositions imaginées vont toutes dans le sens d’une malléabilité, voire d’une “jouabilité” des algorithmes de recommandation. Les participants reconnaissent leur intérêt et acceptent, dans certains moments, de s’en remettre à ces algorithmes et à leurs propositions. Mais ils souhaitent interagir avec eux et retrouver des prises qui leurs permettent de les adapter à leurs pratiques et à leurs envies : de la recommandation, oui, mais qui intègre tel paramètre de l’environnement ce jour-là ; qui me propose volontairement des choses radicalement différentes un autre jour ; qui apprenne que j’apprécie ce type de titre, mais moins régulièrement, etc. En somme, remettre de l’humain dans les algorithmes est autant un enjeu de design des algorithmes que de design du service !
.